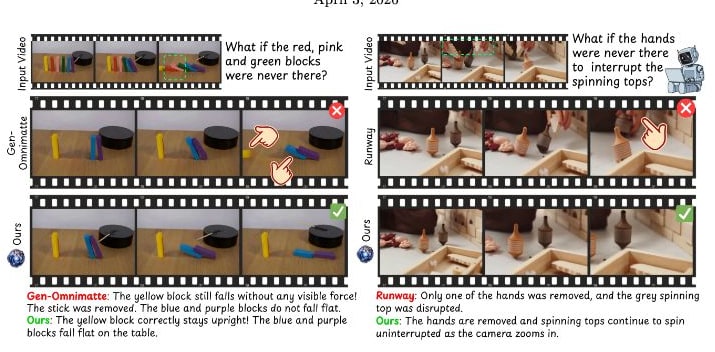
Existing video removal tools are surprisingly good at magic. You can paint over a stray tourist in your vacation footage, and AI will replace them with a reasonably convincing background. But if that tourist was leaning against a wall, or blocking the sun, or holding a leash, the illusion falls apart. The shadow stays. The wall looks weirdly untouched. The dog on the leash is now being held by an invisible ghost.
The problem is that current models treat video editing as a 2D pixel-filling task. They are great at “inpainting” textures, but they have zero concept of causality. The new paper from researchers at Netflix and INSAIT, titled VOID (Video Object and Interaction Deletion), argues that we should stop thinking about inpainting and start thinking about counterfactuals.
Instead of asking “what pixels go in this hole?”, VOID asks: “If this object had never existed, what would the physics of this scene actually look like?”
From pixel-filling to causal reasoning
VOID works by identifying the “causal ripples” an object leaves behind. When you select an object for removal, the system doesn’t just mask those specific pixels. It uses a Vision-Language Model (VLM) to analyze the scene and identify downstream effects … like shadows, reflections, or objects that would have moved differently if the target wasn’t there.
This analysis produces a “quadmask.” Unlike a standard binary mask (remove/keep), the quadmask identifies four distinct zones: the object to remove, the background to preserve, the areas affected by the object’s interaction, and the overlap where the object was physically touching something else. This gives the underlying diffusion model - a modified CogVideoX transformer – a roadmap of what needs to be fundamentally rewritten versus what just needs a texture patch.
The two-pass pipeline and the “jelly” problem
Generating new physics is harder than filling in a static background. In early tests, the researchers found that when the model tried to simulate new motion ( like a ball falling to the ground after the person holding it was removed ) the moving object would often deform, turning into a “jelly-like” version of itself.
To fix this, VOID uses a two-pass generation strategy. The first pass predicts the general counterfactual trajectory (where the object goes). The second pass then uses “flow-warped noise” derived from that trajectory to stabilize the object’s structure. By aligning the diffusion noise with the predicted motion, the model maintains the rigidity of the object even as it simulates an entirely new physical path.
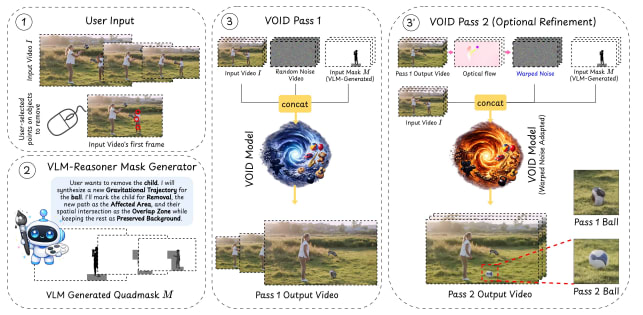
The training data for this was built using Kubric and HUMOTO. Since you can’t easily film “ground truth” for a person being both present and absent in the same physical moment, the team relied on 3D simulations. They rendered pairs of videos: one with a physical interaction (like a collision) and one where the initiating object never existed, forcing the physics engine to calculate the alternate timeline.

Community reaction: A100s and ethical anxieties
The technical community on Reddit and X has been quick to pick up on the project, which Netflix has notably open-sourced on GitHub. While the results are impressive, the hardware barrier is steep. On r/DefendingAIArt, u/Anal-Y-Sis pointed out that the model requires a GPU with 40GB+ VRAM, effectively gating local use to A100-class hardware for now.
On the more mainstream side of the fence, the ability to “rewrite history” so convincingly has triggered immediate concerns about media integrity. In a thread on r/whennews, u/just4browse suggested that the tech will be used to mass censor media by deleting inconvenient objects or actors with zero trace of their original influence.
Others view it as a necessary physics upgrade for the next generation of creative tools, moving us closer to video editors that act like world simulators.
The end of the “clean” plate?
I think the most significant part of VOID isn’t the inpainting quality – it’s the VLM-guided causal reasoning. For decades, VFX artists have relied on “clean plates” (filming the background without the actors) to handle object removal. VOID suggests a future where the clean plate is unnecessary because the AI can infer the “correct” physics of an empty room better than a human can recreate it.
However, the reliance on synthetic data (Kubric) is a double-edged sword. While it provides perfect causal pairs, it’s a far cry from the messy fluid dynamics or complex lighting of a real film set. I expect we’ll see “physics-aware” artifacts in early deployments , where a model might handle a falling ball perfectly but fail to understand how that same ball would splash if it hit a puddle.
The real test for VOID will be how it scales as the backbone models (like CogVideoX) improve. If the underlying model understands the world better, VOID’s “counterfactual” approach only becomes more powerful.

