
The number of pro se legal cases, meaning trials where a defendant or plaintiff represents themselves in court without an attorney, have increased dramatically since the wide adoption of generative AI tools like ChatGPT and Claude, according to a pre-print research paper.
The authors of the paper, titled “Access to Justice in the Age of AI: Evidence from U.S. Federal Courts,” which has yet to undergo peer review, argue more people are representing themselves in court because they’re able to use AI to do a lot of the work that previously required a lawyer. The authors, Anand Shah and Joshua Levy, also say that these pro se cases are “heavier,” meaning each case includes more motions that demand more work out of judges and the justice system. Overall, they argue, the use of AI tools and the increase in pro se cases could put a new burden on the courts.
“If generative AI dramatically lowers the cost of self-represented litigation, the resulting surge in filings could overwhelm a system that depends on human judgment at every stage of adjudication,” Shah and Levy say in the paper.
The paper draws on administrative records covering more than 4.5 million non-prisoner civil court cases between 2005 and 2026 and 46 million Public Access to Court Electronic Records (PACER) docket entries matching those cases. It found the share of pro se cases was pretty stable at 11 percent until 2022, after LLMs like ChatGPT became widely used, at which point it started to rise sharply, up to 16.8 percent in 2025.
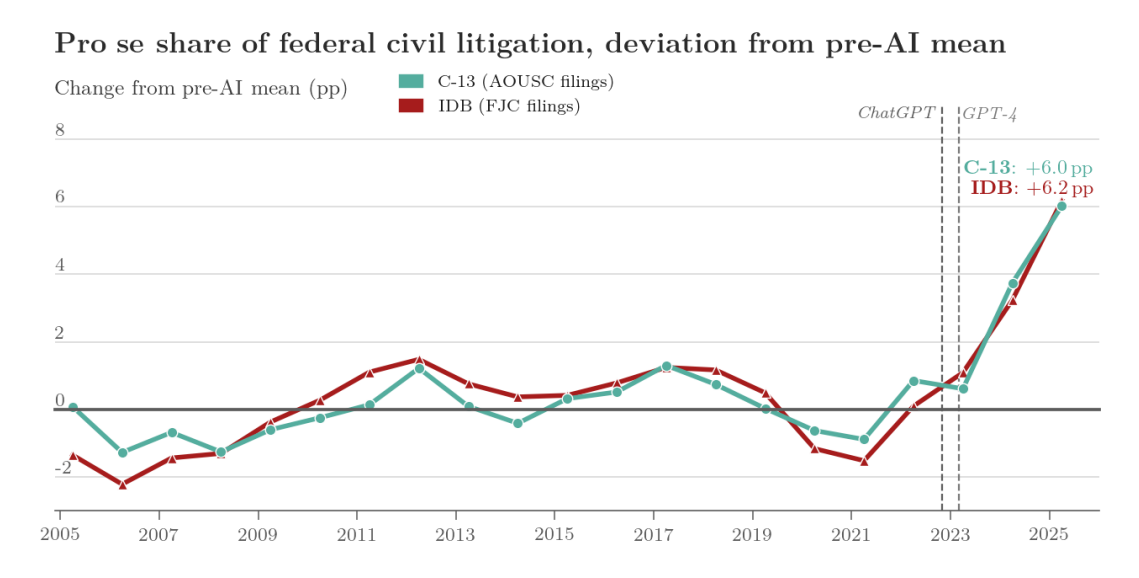
“This stability seems to reflect a structural barrier: for most people, self-representation is prohibitively hard,” the paper says. “Filing a federal civil complaint requires identifying the correct jurisdictional basis, pleading sufficient facts to survive a motion to dismiss, and navigating procedural requirements that vary by context and case type. The widespread, public diffusion of capable LLMs changes that calculus. Without a law degree and at de minimis cost, any person with an internet connection can not only obtain interactive, case-specific legal guidance—drafting complaints, identifying statutes, navigating procedure—but also generate passable legal documents, particularly so after the release of GPT-4 in March 2023.”
The researchers note that the paper is necessarily descriptive, meaning it assumes the rise is due the the prevalence of AI tools, but does not link individual cases to individual LLMs. “We do not claim to identify a causal effect of GPT-4 on pro se filing, only that the observed time series is difficult to rationalize without generative AI playing a role,” the paper says.
To support their argument, the researchers also used a random sample of 1,600 complaints drawn from the eight year period between 2019 (prior to the prevalence of generative AI) and 2026 which they ran through the AI detection software Pangram. They found a rise from “essentially zero” in the pre-AI period to more than 18 percent in 2026.
Notably, it’s not just that there are more pro se cases, but that the “intra-case activity” for those cases, meaning the total volume of activity in those cases as measured by docket entries—filings, motions—are up by 158 percent from the pre-AI period. This means the workload for courts could be even higher that it appears based on the rise in pro se cases alone.
The paper also found that the post-AI rise in self-representation is mostly coming from plaintiffs as opposed to defendants, meaning people are mostly using AI to file complaints rather than respond to them. “Plaintiff-side pro se case counts averaged 19,705 per year from FY2015 to FY2022 and reach 39,167 in FY2025, nearly doubling,” the paper says. “Defendant-side pro se counts fall slightly over the same window, from 4,650 to 3,896.”
“Imagine that you have just a latent level of complaints that could exist in the world, people are constantly getting hurt at work whatever it happens to be,” Levy told me on a call. “But that distribution of potential cases is sort of unchanged over time. But what LLM allowed people to do was it lowered the cost of entry to the courts. Basically, it made it much easier to file many templatable complaints.”
On the one hand, the increase in the number of cases is good because it potentially gives more people with legitimate grievances access to the justice system that they didn’t have previously. On the other hand, a dramatic increase like this could burden the system and make all cases, not just AI-enabled pro se cases, take longer to resolve
“Whether or not it’s a net social benefit is an open question,” Levy said. “But if we remain democratically committed to people having access to the courts as a matter of course then we think that the LLMs have this trade-off. The door to the courts opens wider but maybe the queue to enter gets longer.”
Anecdotally, when we were writing an article about lawyers getting caught using AI in court, we decided to not include pro se cases because there were so many, and to focus only on cases in which actual lawyers were caught using AI. The database we used for that article currently contains 1,353 cases; 804 of them are from pro se cases.
To handle this surge in demand for the Federal courts, Federal courts have to somehow increase its supply, or the courts’ capacity to take on cases. Unfortunately, as the paper notes, “there is no easy margin along which to ‘buy’ extra judge capacity. Already case backlog is becoming a persistent feature of the federal judicial system, there is no coming influx of judges to supply additional capacity, and federal courts in the United States cannot wholesale decline to hear cases.”
Levy suggested that one possible solution is to allow judges to use AI tools to do some of their “templatable” work as well, while still ensuring that human judges do the actual judging.
We’ve covered many instances of lawyers getting caught using AI in court, often because the AI hallucinated a citation of a case that didn’t actually exist. Judges are pretty mad when this happens and have issued fines for this behavior several times.

