
Google DeepMind released Gemma 4 on Easter weekend, and the local AI community responded like it was Christmas. The family spans four sizes – E2B, E4B, 26B A4B (MoE), and 31B dense – with the 31B landing on Hugging Face under an Apache 2.0 license. That licensing change matters: previous Gemma releases used a custom Google license with usage restrictions. Apache 2.0 removes that friction for commercial deployment.
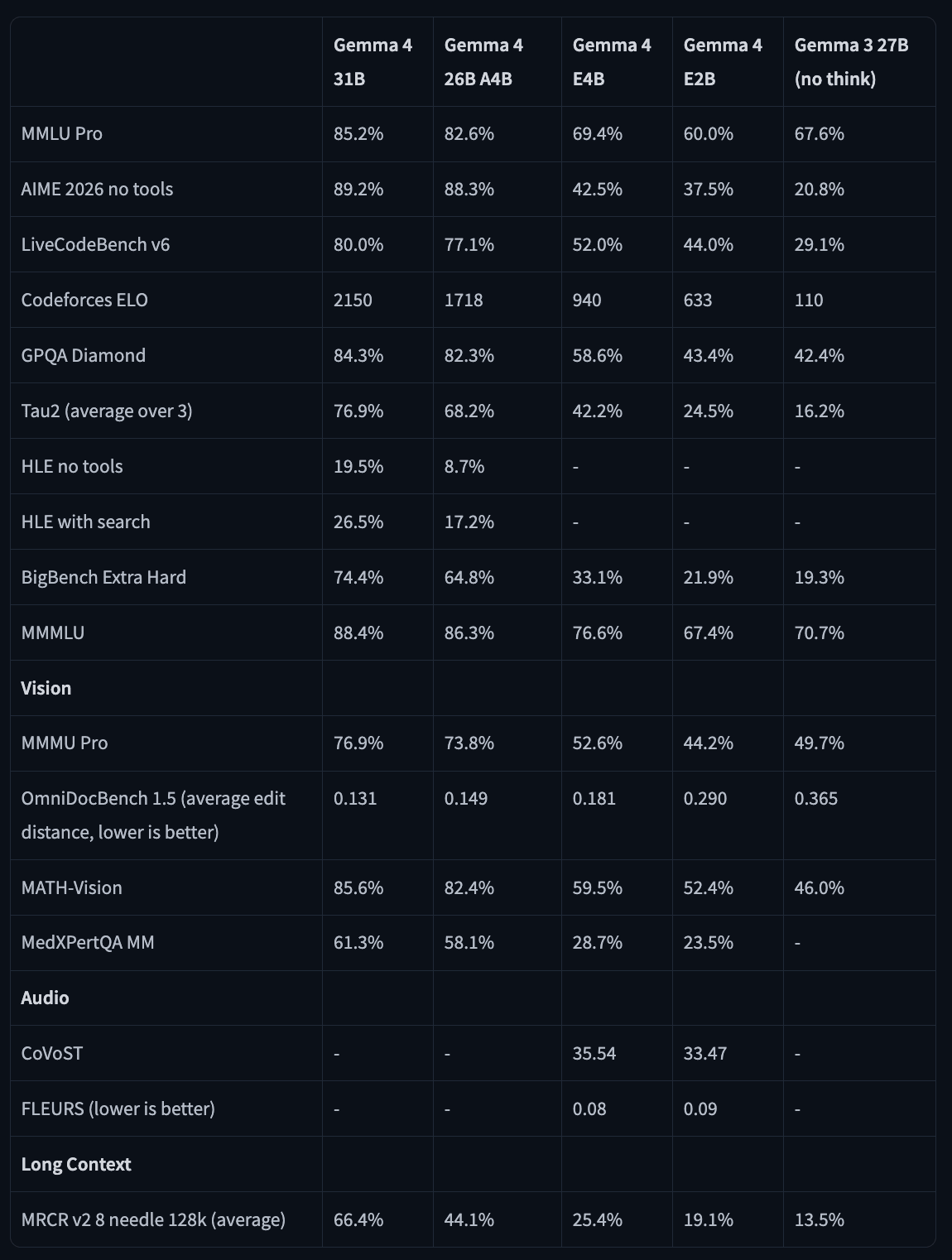
The benchmark numbers are good. The 31B scores 89.2% on AIME 2026 without tools, 80% on LiveCodeBench v6, and a Codeforces ELO of 2150. For comparison, Gemma 3 27B scored 110 on that same Codeforces benchmark. The smaller E2B model – which has only 2.3 billion effective parameters – outperforms Gemma 3 27B on MMLU Pro (60% vs 67.6%), GPQA Diamond (43.4% vs 42.4%), and LiveCodeBench (44% vs 29.1%). Some users called it “insane” – a fair reaction.
What the 31B actually does
The 31B is a dense model with 30.7B parameters, a 256K token context window, and a hybrid attention mechanism that interleaves local sliding window attention (1024-token window) with global attention layers. The final layer is always global. For long-context tasks, global layers use unified Keys and Values with Proportional RoPE (p-RoPE), which is how Google gets memory efficiency at scale without completely tanking reasoning quality.
Multimodal support covers text and images, with a 550M-parameter vision encoder. The model can process images at variable resolutions using a configurable token budget (70 to 1120 tokens per image) – lower budgets for speed on classification tasks, higher budgets for OCR and document parsing where fine-grained detail matters. The smaller E2B and E4B models additionally support audio input for up to 30 seconds, enabling single-model pipelines for voice applications.
Thinking mode is built in and configurable. Include <|think|> in the system prompt to activate it; remove it to disable. The model outputs its reasoning trace in <|channel>thoughtn[reasoning]<channel|> blocks before the final answer. In multi-turn conversations, you strip the thinking content from history before the next user turn – thinking traces don’t get passed back.

Coding is a clear strength. The 31B’s Codeforces ELO of 2150 is a significant jump from anything in the open-weight space at this size. On r/LocalLLaMA, u/DigiDecode_ posted a screenshot showing the 31B ranking above GLM-5 on LMSys, which landed with some force given GLM-5’s reputation.
How to run it
The model is available on Hugging Face and loads through the standard Transformers interface. For text and image inputs:
pip install -U transformers torch accelerate
from transformers import AutoProcessor, AutoModelForCausalLM processor = AutoProcessor.from_pretrained("google/gemma-4-31B-it") model = AutoModelForCausalLM.from_pretrained("google/gemma-4-31B-it", dtype="auto", device_map="auto")
Use AutoModelForMultimodalLM instead if you’re working with images or video (or audio on the E2B/E4B variants).
Recommended sampling parameters from Google:
-
temperature=1.0 -
top_p=0.95 -
top_k=64.
For thinking mode, pass enable_thinking=True to apply_chat_template and use processor.parse_response() to separate the thinking trace from the final answer.
GGUF quantizations are available via Unsloth. NVIDIA also offers a free API endpoint at build.nvidia.com at 40 requests per minute, which is useful for evaluation before committing to local deployment.
For local inference, Google’s recommended config for llama.cpp: --flash-attn on, --temp 1.0, --top-p 0.95, --top-k 64, --jinja. You’ll want KV quantization unless you have unusual amounts of VRAM available.
The KV cache problem
This is where the reception gets complicated. The 31B has a massive KV cache footprint – a consequence of its multimodal architecture. On reddit, users reported that on a 40GB VRAM card, the Q8 quantization (35GB) can’t fit even a 2K context without also quantizing the KV cache to Q4. Qwen3.5-27B, by comparison, fits at full context without KV quantization on the same hardware. A llama.cpp update since release improved this by properly implementing Sliding Window Attention, which reduces the fixed KV allocation significantly – but you need to re-download the Unsloth quants if you grabbed them at launch.

